Open Permits and the power of open source software
Simon WorthingtonThis post is based on a presentation I gave at the British Computer Society’s Open Source Specialist Group Septempter 2018 meetup.
Personal Data Exchange was a project I was involved in at GDS. We investigated how to enable one part of Government to re-use data held by another part of Government, in order to save time and effort of everyone – citizens, services and data holders. Our idea at the time was to try and build digital infrastructure – get departments connected to a network and have them share data in a controlled way. Here, I examine the opposite approach and look at how we could make the permits and licenses we give to citizens more suitable for reuse.
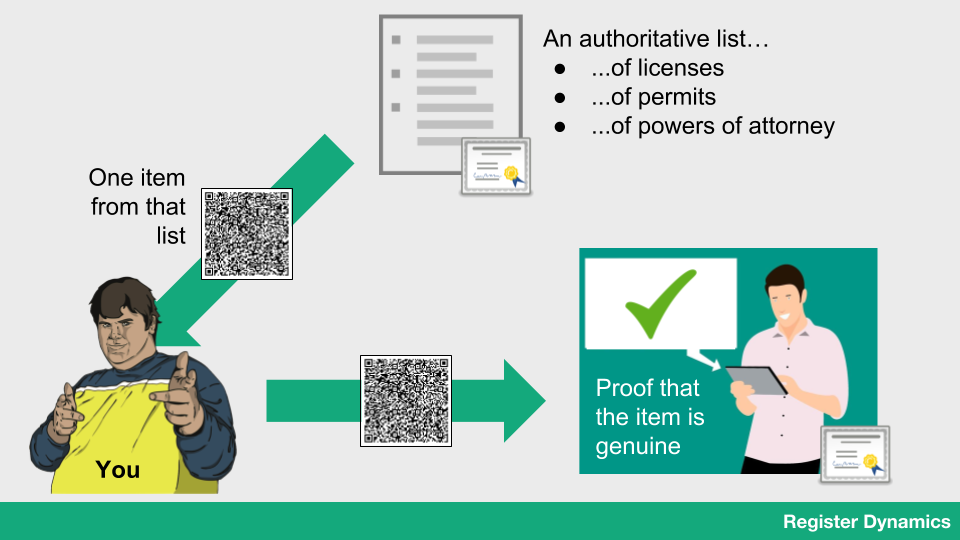
Information that’s useful to people is stored in a list (maybe in a database, or maybe it’s a spreadsheet). The list is exclusive in some way – only people who meet a certain criteria can be on it. It could be a list of licenses (person X has a license to operate a vehicle) or permits (person X has a permit to park here) or something completely arbitrary (person X is on the guest list for my birthday party). Individual items on the list are given out, currently in the form of letters of assessment, license cards or permits, and then these are presented as proof that someone has a meaningful status.
But we’ve seen evidence that collecting and checking this evidence is time-consuming. What if we can do more with these physical proofs? What if we encoded the data in a machine-readable way, that also allowed the data to be verified as accurate? I’ve taken the open-source Registers technology that lets people build secure lists and packed individual items into QR codes, and then built a scanner app that runs on a smartphone and can read and verify the data. List owners can give out individual items as QR codes, which can be scanned and checked by people providing a service.

The advantages of this technology are that verification doesn’t need access to the full list and it doesn’t even need to be online – everything needed to verify the item is in the QR code. The list owner just needs to publish the list “root digest” – a cryptographic number that represents the contents of the list without allowing those contents to be derived. And the fact that it’s open source and runs on a smartphone means anyone can make a list, receive QR codes or perform scans – it’s open to all.
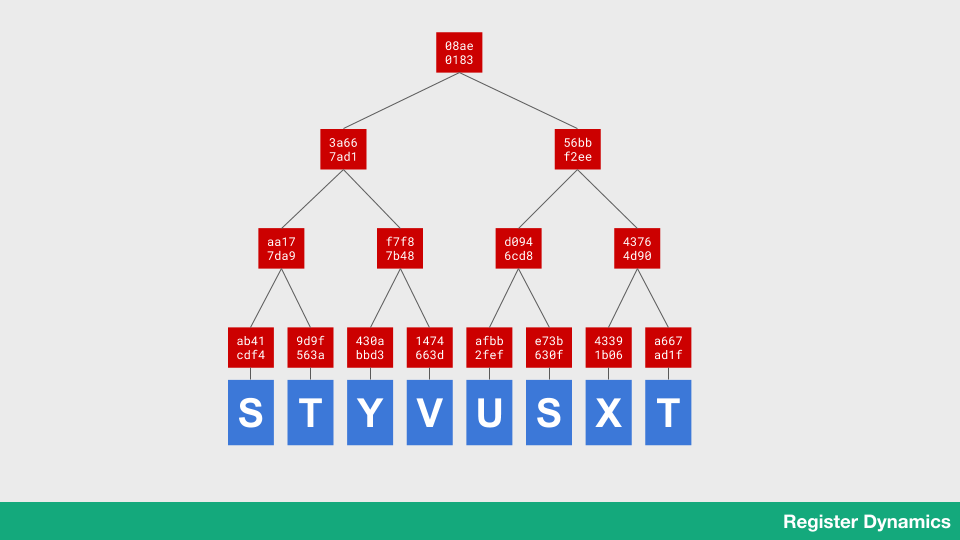
So how does it work? Well, let’s start with the lists themselves. As I mentioned, the lists are actually Registers – append-only lists that are backed by what’s called a Merkle tree. Items in the list (shown in blue) have their “cryptographic hash” computed: we run the content through a special mathematical function that returns a unique number. The number is dependent on the content, so if I change the content the number changes, and if I run the function twice over the same content I get the same number. The function is “one way” – if all I have is the hash, I can’t recover the data. The “hashes” are shown in red.
So I run the function over each item (blue) and get the hash (red). Then I put pairs of hashes together, and run the function on them – this gives me another hash. I keep doing this until I’ve hashed everything down into a single hash – the root hash (that’s the one at the top). This number represents the entire contents of the database – if a single byte of any item changes, this root hash will change too.
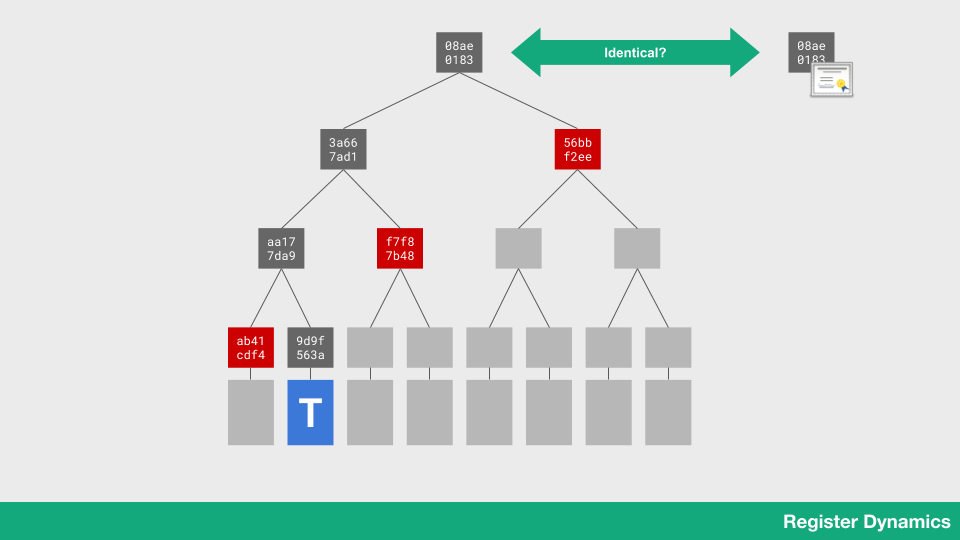
This structure of hashes has a special property. I can give out to you an individual item from the list, and you can compute it’s hash (in grey) because the hash only depends on the content of the item itself. I can then give you a couple more specific hashes (in red) for parts of the list which I’m keeping secret from you. You can combine successive pairs of hashes together, starting with the one you worked out from your data, and eventually calculate the root hash. Notice that you didn’t need the whole list to do that.
The owner of the list will publish the root hash – it’s small and doesn’t leak any data. If you get the same root hash as the one that’s been published, that means you can be sure the item you got is in the list. If it wasn’t, there wouldn’t be any way for you to combine the hashes to end up with the root hash. And if you don’t get the same number, you know something has gone wrong – the data you’ve been given can’t be accurate.
{
"audit": [
"53bThndGiiu4cpL72ZiJKlpgPk1on0BsybHi7H15Puw=",
"lEVe9Bk-qvRx8KC0MP5wfMXpaeJSX9GLAtqnIWXhyBo=",
"Niwo683PBAZZXhoCDi5S576O5LNx8cG_bFu3iniU2B0="
],
"index": 14,
"register": {
"size": 14,
"name": "charity"
},
"entry": "(entry user (key 1129776) #(srfi-19-date 0 57 36 18 20 7 2018 0 UTC #f 5 201 #f) ((item (item-ref opaque (994)) {\"End date\":false,\"Start date\":\"2018-01-01\",\"charity\":\"1129776\",\"Name\":\"King Edwards School Trust\"})))"
}
For the technical people, this is the JSON that’s contained in a QR code. The entry contains the actual data – some metadata and then in curly braces some more JSON. This entry is what gets hashed. There is also some more metadata: the audit key contains the hashes you need to walk up the tree, and the index and size numbers tell you what entry in the tree you’re starting from. You can read more about the algorithm in RFC 6962 and find the example code on GitHub.
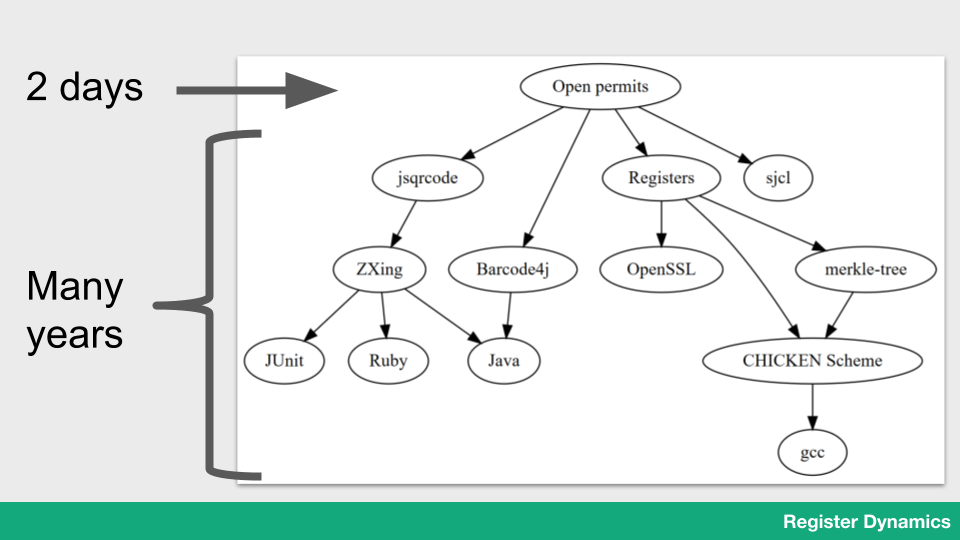
Part of the point of showing this was to demonstrate a particular power of open-source software – I was able to make this demo in just a couple of days, but I could only do that by using high-level open-source libraries that others have spent years writing. Even if I was just to start another level down, I’d have to spend months writing image processing, database and cryptographic code.
It struck me that this picture looks a bit like a mountain – I could push the boundary of what’s technically possible higher by starting from the top of a mountain of existing open-source work. And that’s why we have to keep contributing – it’s the only way to push the mountain higher.
 Simon Worthington
Simon Worthington
Simon is a founder of Register Dynamics, a data consultancy on a mission to make data more useful for everyone, and the creators of Registers.app.
As a technologist with years of experience applying cutting-edge data technology to meet real user needs, Simon gets that data is hard. Tell him your data problems on Twitter @RegDyn!